Full Collection Jobs
We've previewed data to see its shape, and we've done discovery to understand the scope of what we're ingesting. Now, let's go ahead and ingest it. We're going to use the same parameters we did in the Discovery run to complete our investigation scenario. First, let's take a quick look at the Elasticsearch environment to verify that there are no events in it already.
- Click the
Kibana - Eventsupper tab. It should show you a normal Kibana Discovery page, but with no events, like this:
Now, we're going to do the Full Run version of the Discovery job we ran before, so we need to enter the same filter components into the Run modal again.
- Click the
Criblupper tab, then withManageactive in Stream's top nav, selectDataand click onSources - Click on the
Collectors S3tile from theData > Sourcespage. - Click the
Runbutton next to your configured collector, and theRun configurationmodal will appear. - In the
Run Configurationmodal, set theModetoFull Run. - Change the Time Range to
Absolute - In the
Earliestfield, use the date picker to select May 5, 2021 and hitOk. - In the
Latestfield, use the date picker to select May 10, 2021 and hitOk. - In the
Filterfield, enter:src_zone=='trusted' && dest_zone=='trusted' - At this point, the screen should look something like this:
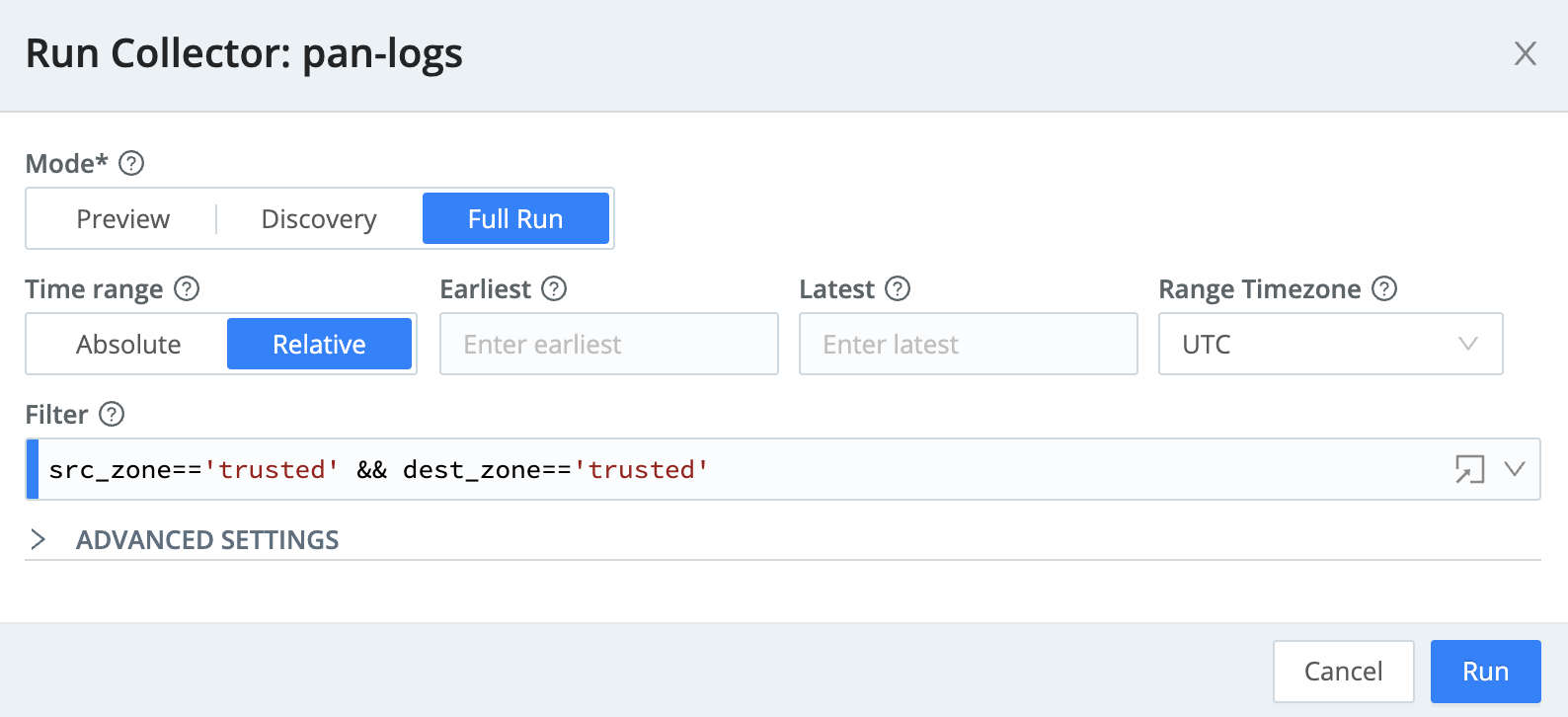
- Click
Run.
It should take about 3 minutes to run the job - feel free to grab a cup of coffee or tea... 😃
While you're waiting, feel free to take a look at the Job Inspector (just like we did for Discovery). This will return you to the collector's configuration. If you click the link under Latest Ad Hoc Run, you'll see the throughput of your running job, along with results, like this:
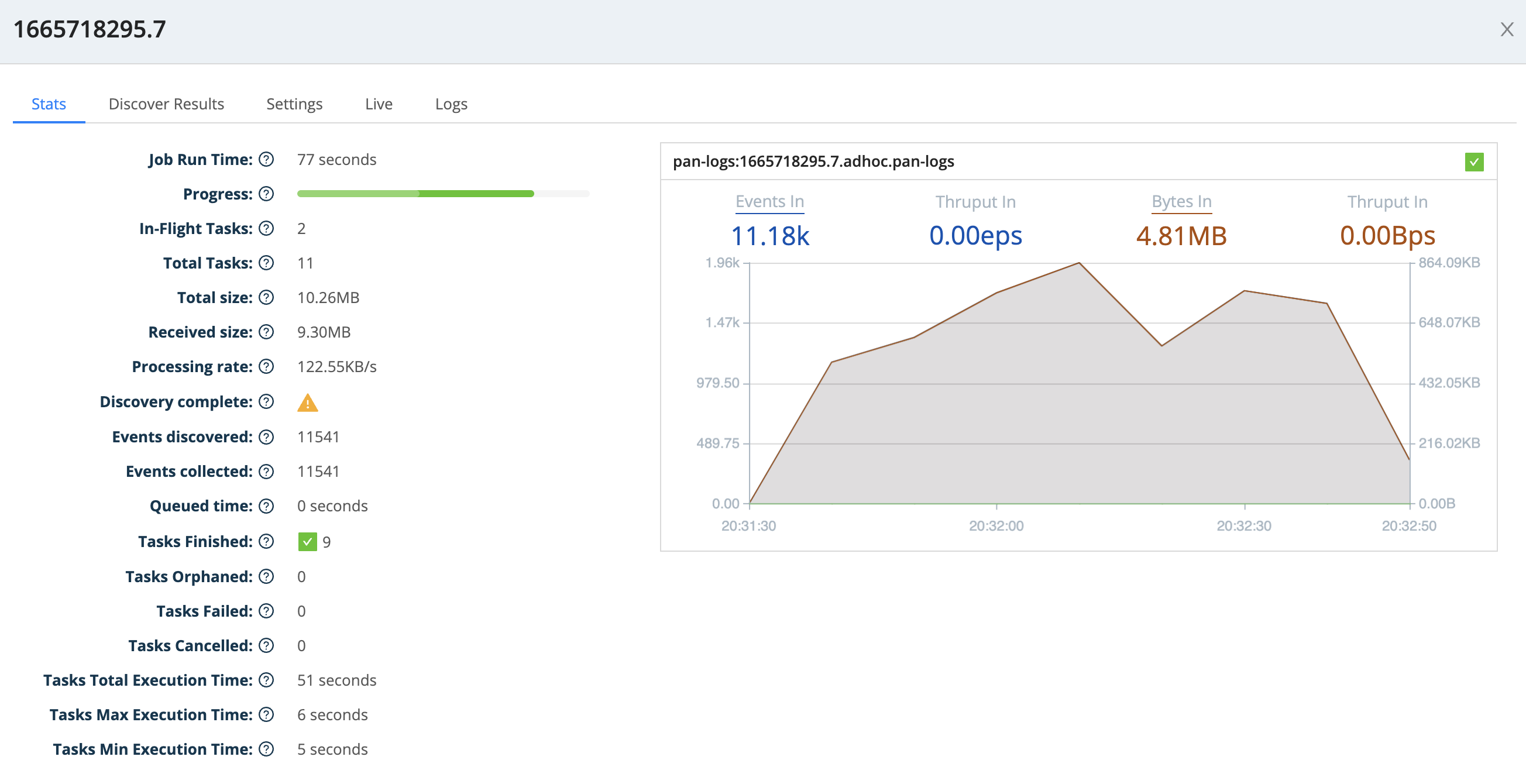
Once the job is complete (i.e., the Job Inspector shows a status of Finished for this job's row), go back to the Kibana - Events upper tab, and click Kibana's Refresh button. You should now see events in the May 5–10 2021 date span, like this:
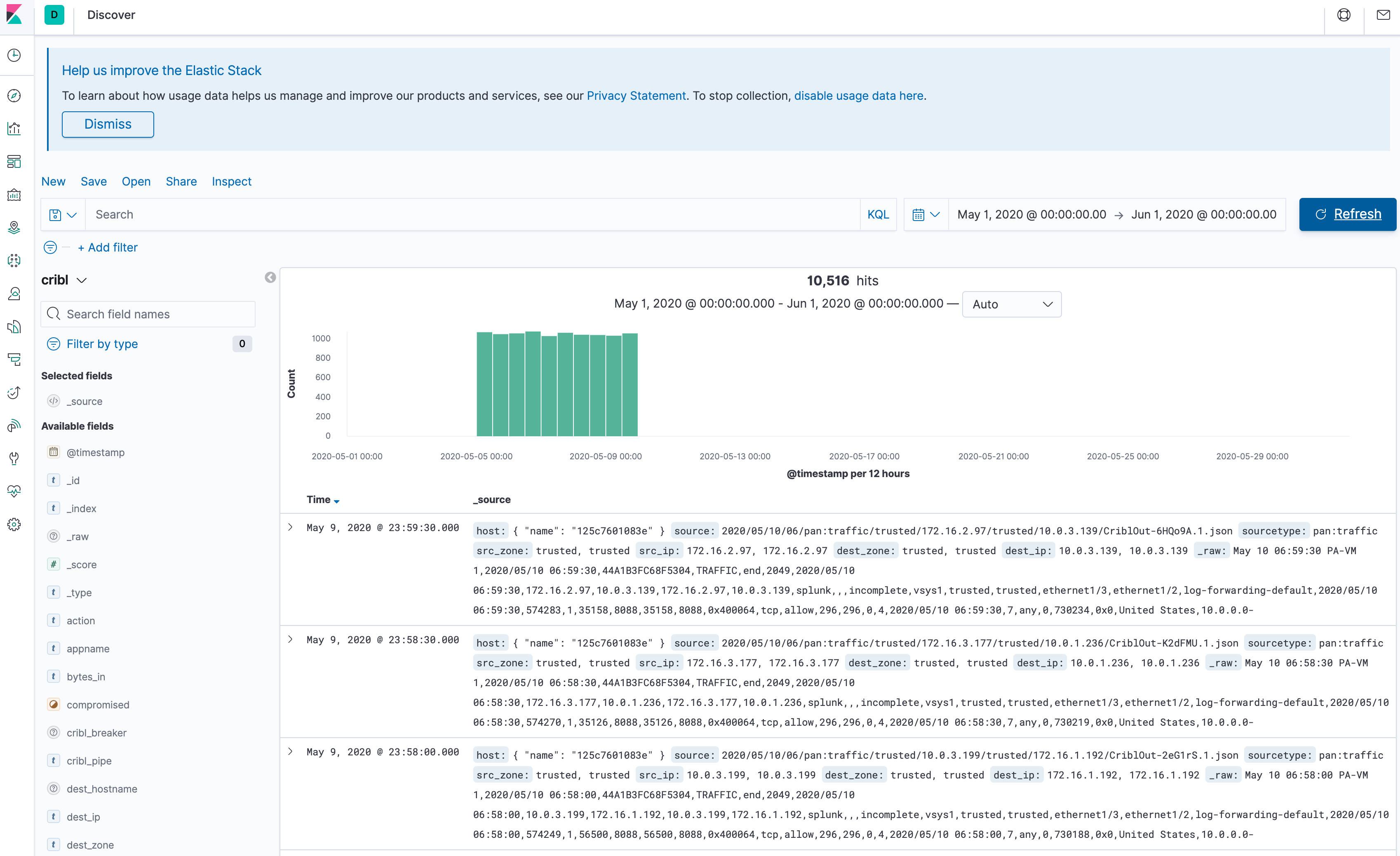
Congratulations - so far, you have:
- Configured a Data Collector
- Previewed the data that it will collect
- Run a discovery job to understand the scope of the collection, and
- Run a data collection job, feeding the collected data into Elasticsearch/Kibana.
That's great! By using a combination of archiving your data to S3, and using Data Collection to reingest it when you need to, you can separate your retention requirements from your analysis requirements. But we want to explore this capability a bit more, and use this data to generate batch metrics.