Discovering Data
Since Data Collection jobs can filter the collected data, it's useful to first figure out what data a job will bring in. For this purpose, Stream provides the capability to do Discovery jobs.
A Discovery job is effectively a dry run of a full job. It walks the data store, finding all data that matches the specified filter, and keeps track of what it would retrieve if a full job were run. This allows you to test out your filters before an actual full run, tuning your run to get just the data you want.
Let's imagine that we're doing an investigation on a security incident that occurred between May 5, 2021 and May 10, 2021. In our imaginary incident, we need to look at east-west internal traffic. When we go back to our partitioning scheme, we can use the fields we captured in the collector to filter the data.
- If you're not already here: Click
Criblon the top row of tabs, then withManageactive in Stream's top nav, selectDataand clickSources - Under the
Collectorssection, clickS3. - Click the
Runbutton next to your configured collector, and theRun configurationmodal will appear. - Set the
ModetoDiscovery. - Change the Time Range to
Absolute - In the
Earliestfield, use the date picker to select May 5, 2021 and hitOk. - In the
Latestfield, use the date picker to select May 10, 2021 and hitOk. - In the
Filterfield, enter:src_zone=='trusted' && dest_zone=='trusted' - At this point, the screen should look something like this:
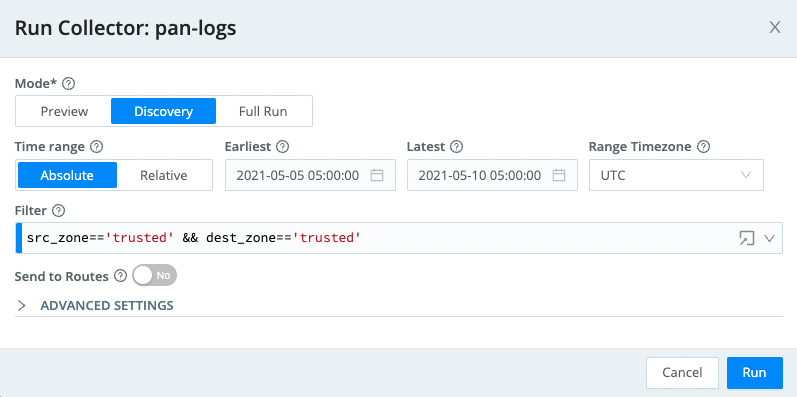
- Click
Run.
Once the job starts, you'll be returned to the collector configuration page, and you'll notice a job ID show up in the Latest Ad Hoc Run column, like this:

Clicking on that job ID will bring up the Job Inspector. If you click its Discover Results tab, you'll see something like this:
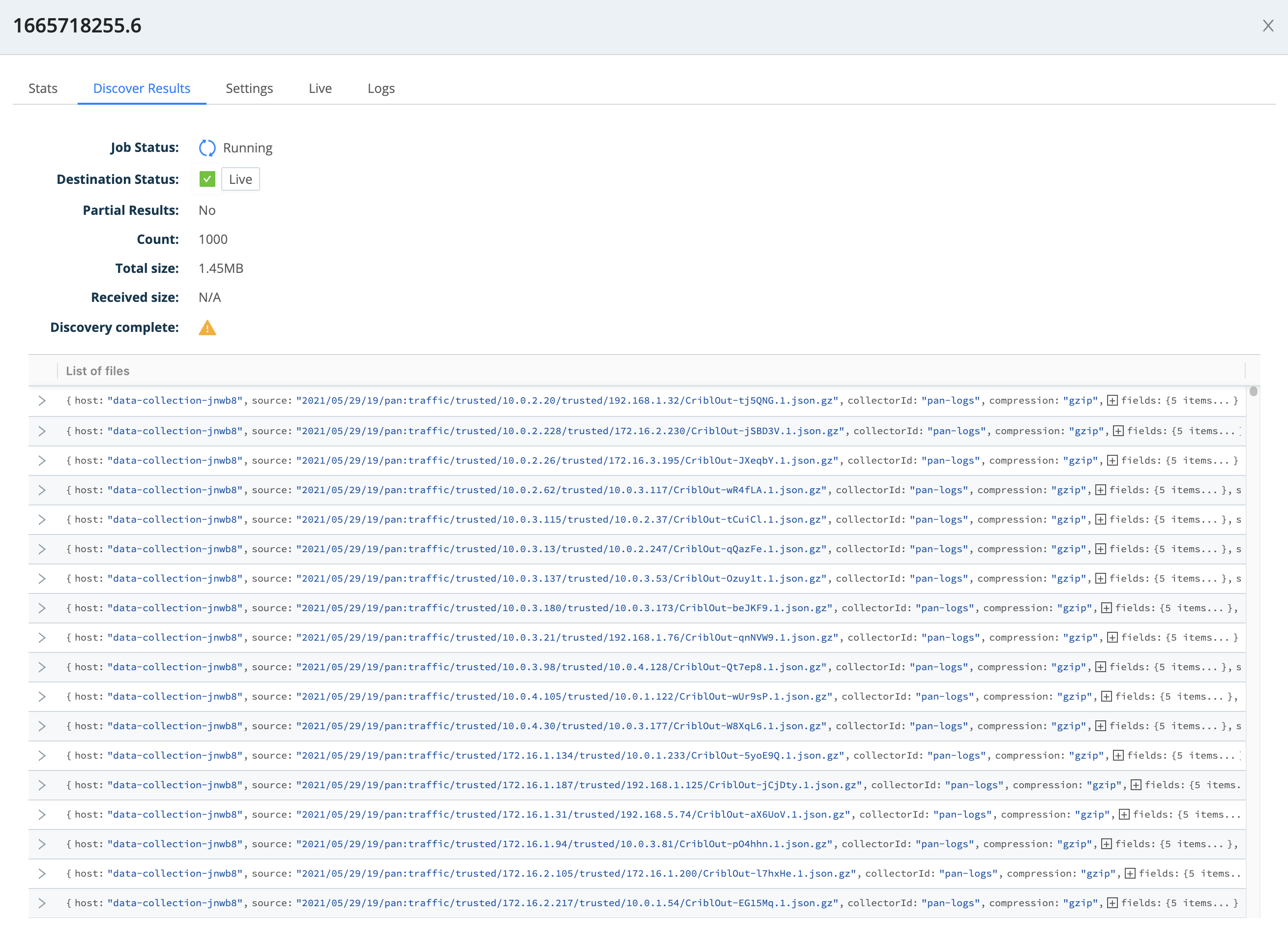
As you can see, this shows you approximately how many objects (files) a Full Run collection job will pull from the datastore.
Play around with changing the filter and re-running the Discovery job, to see how changing the filter can change the results. The filter is an effective place to zero in on the data that you're specifically looking for, before you ingest it.