Configuring a Data Collector
Let's configure our collector.
-
Click
Criblon the top row of tabs, then withManageactive, selectDatain the Stream top nav and clickSources, then click on theS3tile under theCollectorssection. -
On the
Manage S3 Collectorspage, clickAdd Collector -
In the
Collector IDfield, enterpan-logs -
In the
S3 bucketfield, enterlogarchives -
In the
Regionfield, selectUS East (N. Virginia) -
In the
Pathfield, enter:/${_time:%Y}/${_time:%m}/${_time:%d}/${_time:%H}/${sourcetype}/${src_zone}/${src_ip}/${dest_zone}/${dest_ip}/(You can click the
Copylink at the upper-right corner above to put this on your clipboard.)This both mirrors the partitioning scheme from the Exploring Data At Rest portion of the course, and extracts the elements from the partitioning scheme into fields that we can use for filtering:
- sourcetype – the sourcetype of the data
- src_zone – the zone from which the source IP enters the firewall.
- src_ip – the IP address of the source system
- dest_zone – the zone through which the traffic egresses to get to the destination IP.
- dest_ip – the IP address of the destination system.
- _time is also extracted via this scheme, allowing us to filter by time.
-
Expand the
Authenticationsection, switch the method fromAutotoManual, then enter these credentials in theAccess keyandSecret keyfields:Access key Secret key ACCESSKEYSECRETKEY
At this point, your screen should look something like this:
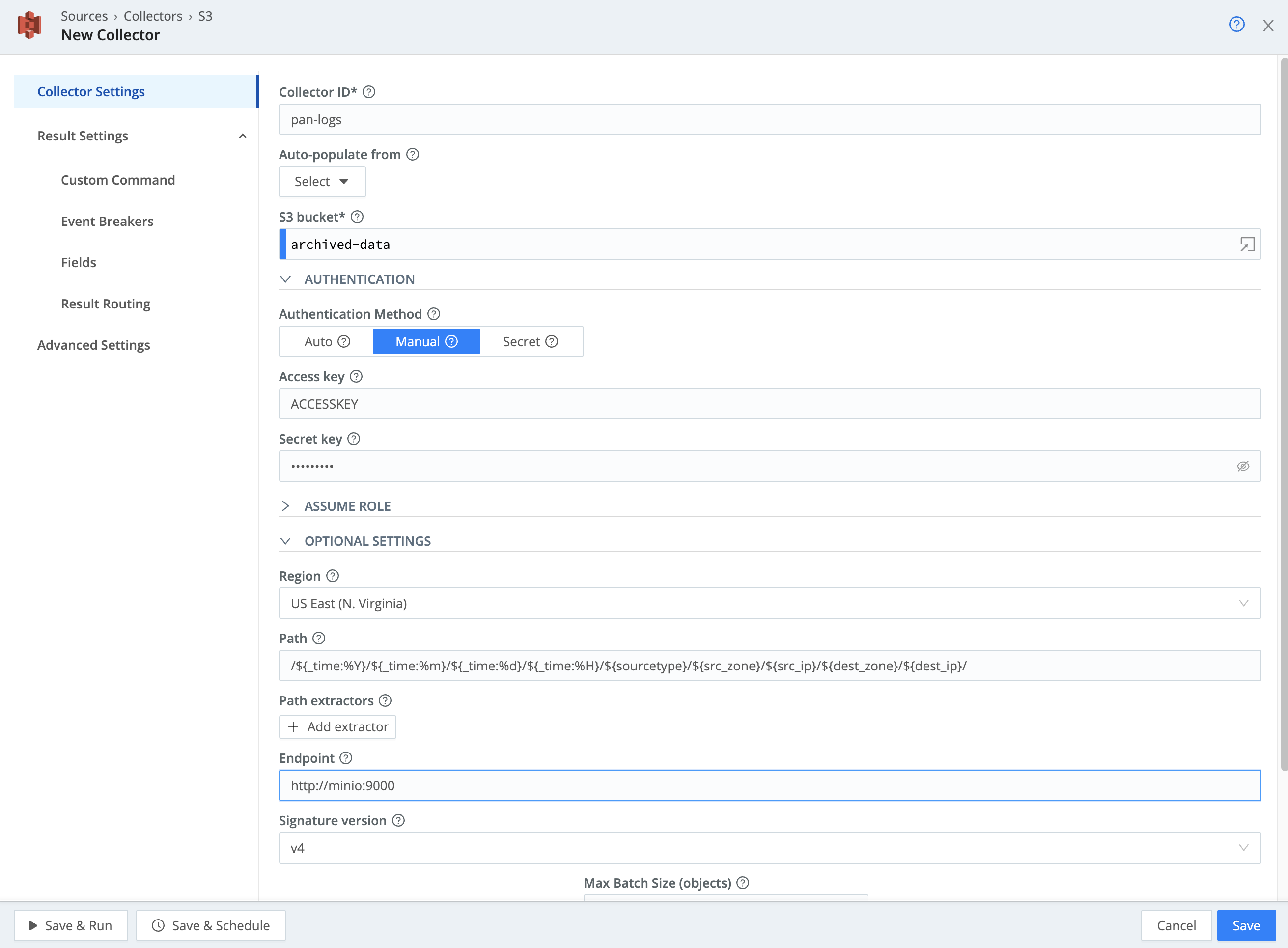
A note about the S3 setup: Since we're using a local MinIO instance, we're using the default credentials (ACCESSKEY/SECRETKEY). We'll also need to specify an API endpoint (you don't need to do this with native S3).
- Under
Collector Settings, expand theOptional Settingssection. - In the
Endpointfield, enterhttp://minio:9000/ - Next, click the
Event Breakerstab on the modal's left edge. - Click
Add ruleset, and a new field will appear. In thatEvent Breaker rulesetsfield, pull down and select theCriblruleset. - Select the
Result Routingleft tab, and ensure thatSend to Routesis set toNo. - For now, we're going to use the
passthruPipeline, so in the Pipeline field, selectpassthru, and in theDestinationfield, select theelastic:elasticentry. - Leave everything else with default values, and click
Save.
A couple things to mention here:
-
As data comes in from the collector, it's bundled into a collector event, placing the original event in the
_rawfield in a JSON object. But we want all the fields of the original event, so we need to do one of two things: use an Event Breaker that pulls the events apart properly, or use a Parser function in a Pipeline to extract the data. In this case, we're using the Event Breaker - the Cribl event-breaking rules handle the event extraction for us. -
In our use case, we're doing an investigation on a single type of data. We don't need the full power of the routing system, so instead of sending the collection data through the Data Routes system, we're setting a specific Pipeline and Destination for all events from the collector to go through. If you're replaying all of your data from a specific time, you might want to utilize Data Routes to process all the data as it would had it streamed in. In our case, we don't need to.
-
It's also worth mentioning the
Auto‑populate fromfield back inCollector Settings. In your own environment, if you have an S3 destination configured for your archive, you can click this and select that destination, filling in all of the configuration fields for that destination. This makes it easier to configure collection from your archive destination.