Course Overview
Cribl, the Data Engine for IT and Security, empowers organizations to transform their data strategy. Customers use Cribl to collect, process, route, and analyze all IT and security data, delivering the flexibility, choice, and control required to adapt to their ever-changing needs.
Organizations we've spoken with have repeatedly told us they would like to be able to collect and analyze 5–10x more data than they can currently afford. These organizations are struggling with the cost of the systems they're already running.
Much of the data to be collected may be very high-volume but lower-value. It may be needed for compliance, or in the event of a breach investigation. In operational use cases, high-volume time series event data may be best aggregated and stored as metrics, while putting the full-fidelity event data in cheap storage, in case the need arises later to do full analysis. That data could also be sent to an analytics store like Snowflake, Databricks, or Redshift.
In effect, people are often treating their current log analytics system as a system of record, when in reality there are far more cost-effective ways to store this data. Storing log data in an inverted index requires a huge amount of storage, usually 3–8x larger than the same data as stored in compressed log files.
If you need fast needle-in-a-haystack search performance, you need to store the data in log analytics storage, and pay for the optimization of fast search. But, that should only be a subset of your data. You can offload a full-fidelity copy of your data to much more cost-effective storage, like Amazon S3 or an API-compatible destination like MinIO.
Routing
One of the key capabilities Cribl Stream offers is selective routing of data. One of the most exciting use cases for routing is connecting an existing, deployed footprint of agents, like the Splunk Universal Forwarder, and allowing it to write to multiple destinations. Stream makes it easy to put a subset of the data into a log analysis system like Splunk, and to put all (or another subset) of the data into object storage like Amazon S3 or MinIO.
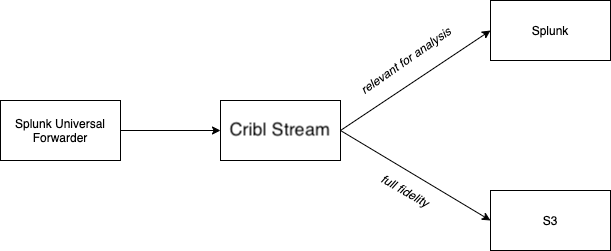
Though the above diagram shows routing to both Splunk and S3, for the purposes of this tutorial, we're just going to be writing to an S3 compatible store, without a Splunk destination.
Parsing & Enrichment
From S3, data can be pulled into analytics stores like Snowflake, Databricks, or Redshift. However, much log data that's collected isn't structured in a way that's easy for normal analysis tools to analyze. Stream makes it easy to parse this data in the pipeline, then enrich it with additional context, to make it more valuable to analyze.
Course Overview
This course will walk through a simple use case of configuring Cribl Stream to route data from a Splunk Universal Forwarder to MinIO. We will learn how to configure Stream to connect to an S3-compatible destination and receive data from a Splunk Universal Forwarder. We will cover the basics of partitioning expressions, to control how the data gets laid out in S3. Lastly, we will also cover basic parsing and enrichment to make the data better shaped for analysis.
Let's get started!