
Connecting Sources & Destinations
Course Map
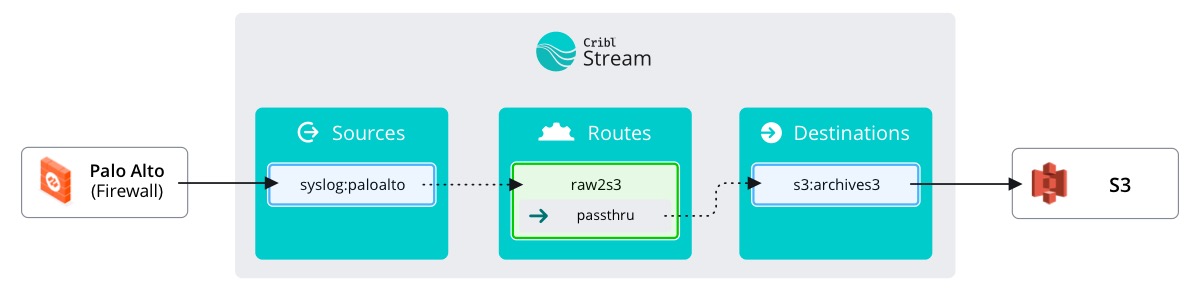
Data routes are how we tell Stream the path data should take. In simpler terms: Data Routes are how we connect Sources and Destinations.
important
Select the Routing submenu click Data Routes
Here we find that Stream comes with a default Route built-in. If you expand it (by clicking the little arrow on the left) we can see a few things about this Route that will help us make our own Route. However, it’s easier to learn by doing!
important
Create a new Route
- Click
+ Routein the top right corner - Name the Route
raw2s3 - Leave the Filter set to its
truedefault - Select
passthruunder Pipeline - Leave the Enable Expression field set to its
Nodefault. - Select
s3:archives3for the Output - Fill out the
Descriptionwith something… descriptive - Toggle
FinaltoNo - Click the top left of the Route (next to the minimized arrow) and drag the new Route to position 1
- Click
Save
What makes a Data Route
Every Data Route starts with a Name. By now you probably sense a pattern; everything starts with a Unique Identifier (Name) so that it can be called elsewhere in the config or internal code.
After the name we get to the Filter. Filters define when a route is used. When a Filter evaluates to true, data will go down that Route. In our use case, we want this to apply to all data coming through Stream. Hence we can just type true. We’ll get into more advanced Filters next time.
A Pipeline is a group of Functions used to transform, enrich, reduce, or redact data. If we want to send all data unalterred to S3 for archival purposes, we want to simply let it passthrough. In other words we want no functions in the Pipeline. Stream has a built-in passthru Pipeline that is aptly named.
Next we move on to Output. This is our Destination. Our Route's purpose is to put our data into S3, so let’s choose archives3.
Lastly, we need to add a Description because we want everyone to be able to understand what we were trying to accomplish.
If we read the route as a sentence it would go something like this, ‘Every piece of data coming into Stream gets passed through to archives3.’ Good work!
Final?
Before we finish we can cover the Final button. This button decides whether or not the data continues to any other Routes we have further down. If Final is enabled, the data stops here. Otherwise, it goes back into the processing engine and hits the next Route that evaluates to true.
At the moment this doesn’t matter because we have one real Route and don’t care if the data continues on, but since we plan to build more Routes, let’s leave Final disabled.
Fin!
Done! Well kind of. If you believe that everything is working, then yeah – we’re done. However, if you like to see proof, then let’s go check out that everything is flowing and then we can be done.