Why do we archive?
Today, we start your Stream journey! A great place to begin your configuration is by copying all data that flows through Stream to an S3 bucket.
Picture if you will – in the future a data breach occurs and Security Operations (SecOps) needs to look back at the old data to find when and where the breach occurred.
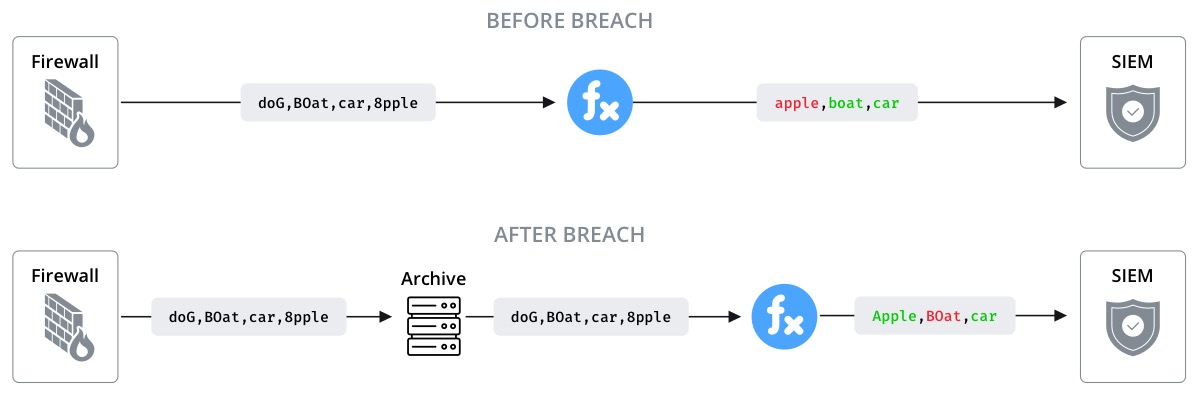
OR maybe today your organization likes vendor 1 for their Security Information and Event Management (SIEM) tool, but tomorrow vendor 2 offers a better solution. How do you get all your old data into the new solution? Wouldn’t it be great if you had a complete copy of all the raw data that ever flowed through your environment?
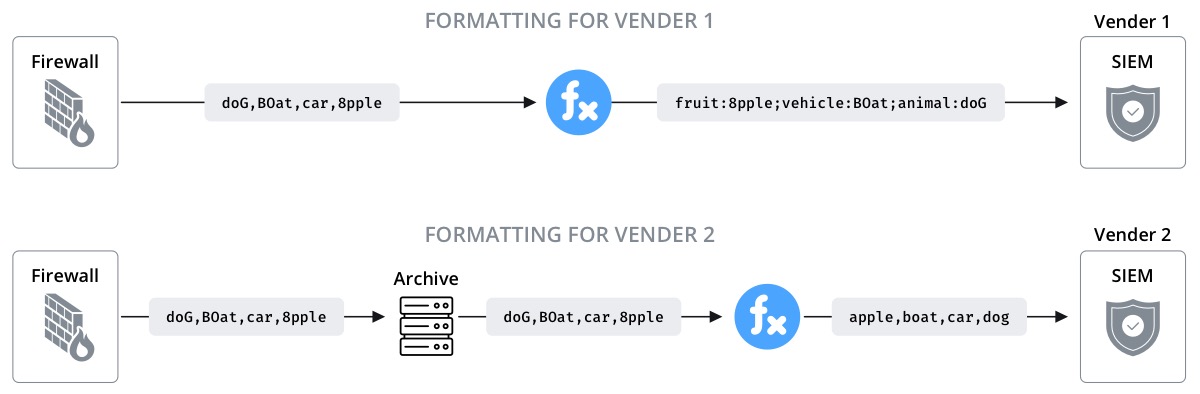
During this course, we will learn how to configure a Pipeline to copy all raw data that flows through your environment to an S3 bucket. This will allow for cost effective long-term storage. We can also use the data again in new ways in the future if the need arises (hint: it will).
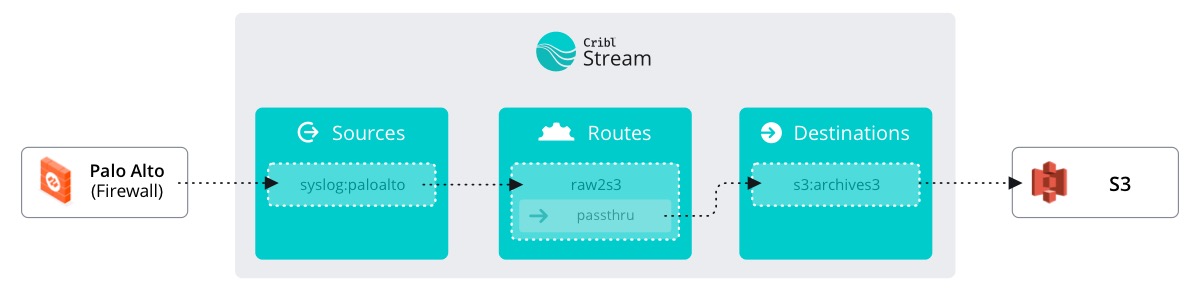
Course Map
As you move through the course, this course map will help you to understand where you are / what you’re doing. Dotted outlines indicate parts of Stream yet to be touched. The green colored box indicates ‘You are here.’ Teal boxes show where you have been.