
It's Gotta Go Somewhere
Course Map
Destinations are just that: Places where our data will end up once it passes through Stream.
important
Select the Data submenu and click Destinations
As you can see here, Stream supports sending data to a lot of Destinations. The world is your data oyster. For this sandbox, we will look at sending all of our raw data to Amazon S3 for cost effective long-term storage. This will allow us to easily reuse or replay the data at a later date if needed.
note
Behind the scenes, the ‘S3’ storage used in the sandbox is actually MinIO. MinIO is better suited for our architecture of the sandbox environments.
Don’t be confused when you see references to MinIO in the coming steps.
Create a Destination
important
Create a new S3 destination
- Click
Amazon S3 - Click
New Destinationin the top right
Here we are met with a plethora of fields to fill out. Only a couple are mandatory, and the rest are pretty simple to explain.
- Output ID - This is the identifier that Stream uses internally so you know what you’re talking about when configuring other aspects of the UI.
- S3 Bucket Name - In the S3 storage area that IT configured, which specific area do you want to store your data in?
- Region - Where in the world is Carmen San Diego? And your AWS instance.
- Staging Location - Before we push the data to S3, where should a temporary copy be stored in case something happens?
- Key Prefix - For advanced users, add a prefix to your file paths.
- Partitioning Expression - Do you want Stream to put the logs in certain directories? If so, what’s the naming convention?
- Data Format - How should the data look when leaving Stream?
- File Name Prefix Expression - Do you want all the files to start with the same name?
- Compress - Should we compress the data when moving it to S3?
- Backpressure behavior - If we can’t reach S3, what should we do?
important
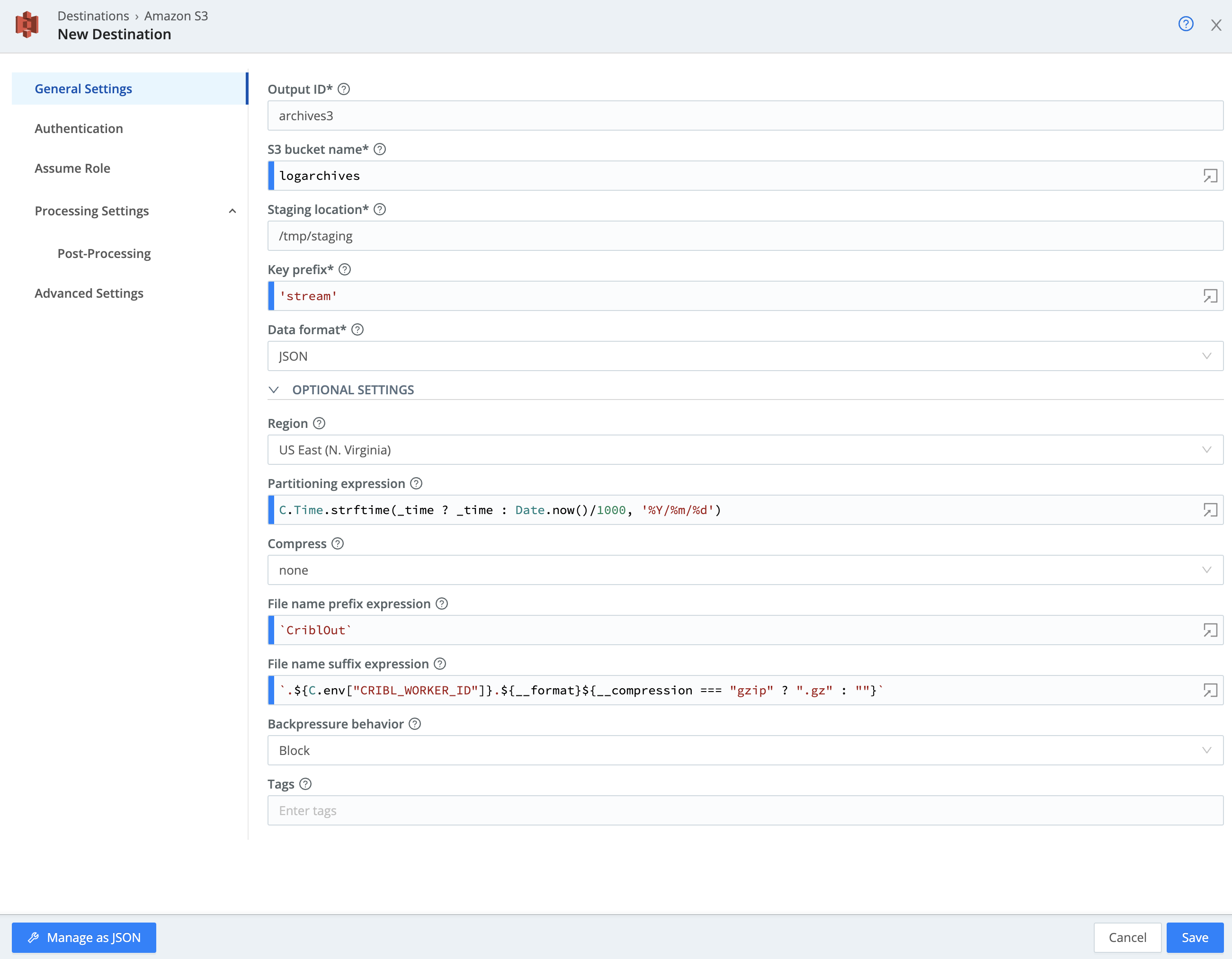
Fill out the fields for the S3 destination (if a field is not included, it can be left at the default value or blank)
- Output ID -
archives3 - S3 Bucket Name -
logarchives - Region -
US East (N. Virginia) - Staging Location -
/tmp/staging - Key Prefix -
'stream'
Your settings should look like the following:
Earlier there was a note confessing that behind the scenes this S3 deployment was actually MinIO under the covers. Well because of this, we need to make two quick stops to complete our destination configuration: Authentication and Advanced Settings.
important
Authentication Configuration
- Click
Authenticationon the left-hand side of the S3 window - Under
Authentication MethodselectManual - Fill out the fields as follows:
Access key Secret key ACCESSKEYSECRETKEY
Advanced Settings in S3
- Click
Advanced Settingson the left-hand side of the S3 window - Under
Endpointenter inhttp://minio:9000 - Click
Save
We can try to verify data flow again by clicking the Live button to the right of our S3 Destination. However, we haven't told Stream to send any data to our Destination, so nothing will show up. Let's go configure that shall we?