Lookup
In this section, we're going to use the Lookup Function to enrich an event, and then use it to make decisions on our data. You might want to enrich an event with data from a threat list, or only allow traffic through from a certain list of network blocks. Lookup enables us to add that context, to use when making decisions.
First, let's create a Lookup file in the UI. For this example, we're going to create a lookup file with just a couple of entries. We'll look up the orderType field against this file.
-
Select the
Processingsubmenu and clickKnowledge.Note: Depending on the size of your window, the top nav will consolidate items that won't fit in a pulldown represented by an ellipsis (
...) - if so, click on the ellipsis and then selectProcesingand click onKnowledge. -
Click
Lookupsat the left. -
Click
Add Lookup Fileat the top right. -
From the drop-down, choose
Create with Text Editor. -
Under
Filename, enteraddOrders.csv. -
In the right pane (one big field), paste the following table:
orderType,addOrder
NewActivation,yes
AddLOS,yes -
Click
Save.
This lookup table shows off one of the simplest use cases for Lookups, which is to enrich events based on a match, to support further routing or filtering logic. In this case, we're going to lookup based on the orderType field, and if we find addOrder, we're going to drop anything that doesn't match NewActivation or AddLOS.
Next, we need to add our Lookup Function to the Pipeline.
- Select the
Processingsubmenu and click onPipelines. - Select
business_eventunderPipelines.
To display this column's header and contents, you might need to drag the pane and column dividers toward the right. - In the right pane, make sure
Sample Datahas focus. - Click
Simplenext to thebe.logcapture. - At left, click
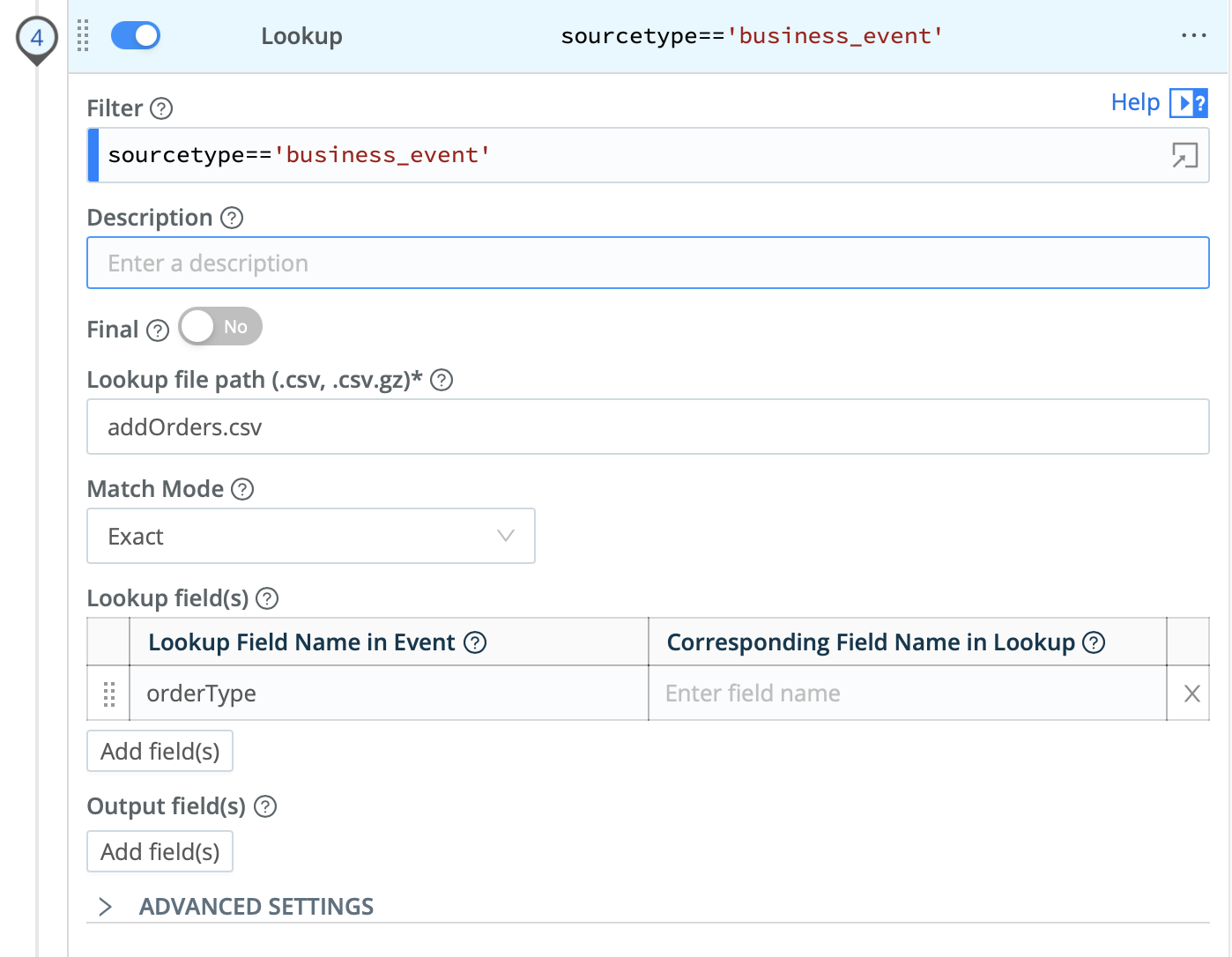
Add Function, search forLookup, and click it. - For the new
LookupFunction'sFilter, enter:sourcetype=='business_event' - Click in
Lookup file pathto open its drop-down. - Select
addOrders.csv, the lookup file you created in the previous section. - Set
Lookup Field Name in EventtoorderType. - Click
Save.
When you're done, your lookup should look like this:
Now, we're going to drop all events which do not match.
addOrder- Click
Add Function, search forDrop, and then click it. - Scroll down and click into the new
DropFunction. - Paste this into the
DropFunction'sFilterfield:sourcetype=='business_event' && !addOrder - Click
Save.
What this is saying, in JavaScript, is: If sourcetypeis business_event, and if addOrder – which we retrieved from the lookup – is not truthy (and it will not be, if the lookup matches), then we want to drop the event. This could also be written as addOrder!=='yes' to match an exact string, or addOrder !== undefined to make sure it's undefined.
Now, all events which are not of orderType:NewActivation or orderType:AddLOS will be dropped. You can see this in the Preview pane. Let's validate with Capture that filtered events have only those two orderType values.
- Click the
Sample Datatab. - Click
Capture Data. - In the
Capture Sample Datadialog, replace theFilter Expressionfield's contents with:cribl_pipe=='business_event' - Click
Capture. - Under
Where to captureselectBefore the post‑processing Pipeline. - Click
Start.
By default, Capture grabs events right as they come into Cribl. We set this capture to instead run after our processing Pipeline runs, meaning that we've already run the Lookup and Drop Functions. The events returned should have an orderType value of only NewActivation or AddLOS.
For our next section, we want all events back.
Drop and Lookup Function- Click
Cancelto close theCapture Sample Datamodal. - In the
LookupFunction's header row, slide theOntoggle toOff. - In the
DropFunction's header row, slide theOntoggle toOff. - Click
Save.
This toggle is an example of retaining a Function in a Pipeline's structure, but disabling it to debug – or in our case, to refine – the Pipeline's behavior.
Next, we're going to explore techniques to control data volume or to completely reshape data – like suppression, sampling, and aggregation.