Why do we archive?
Your Cribl Stream journey begins today! It is a great idea to copy all data flowing through Stream into an S3 bucket as a first step.
Why is this a great idea, you ask? Well Cribl, the Data Engine for IT and Security, empowers organizations to transform their data strategy, enabling customers to collect, process, route, and analyze all IT and security data.
Picture if you will – in the future a data breach occurs and Security Operations (SecOps) needs to examine the old data to find out when and where the breach occurred.
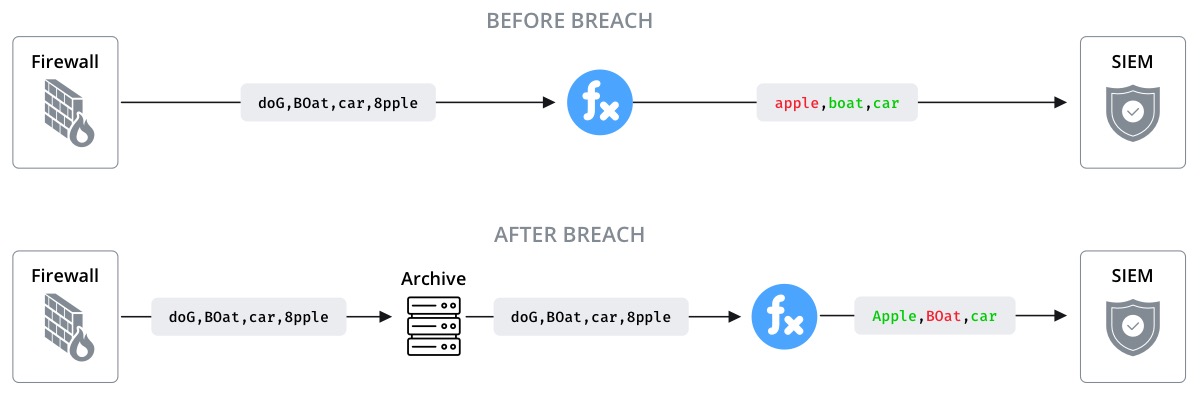
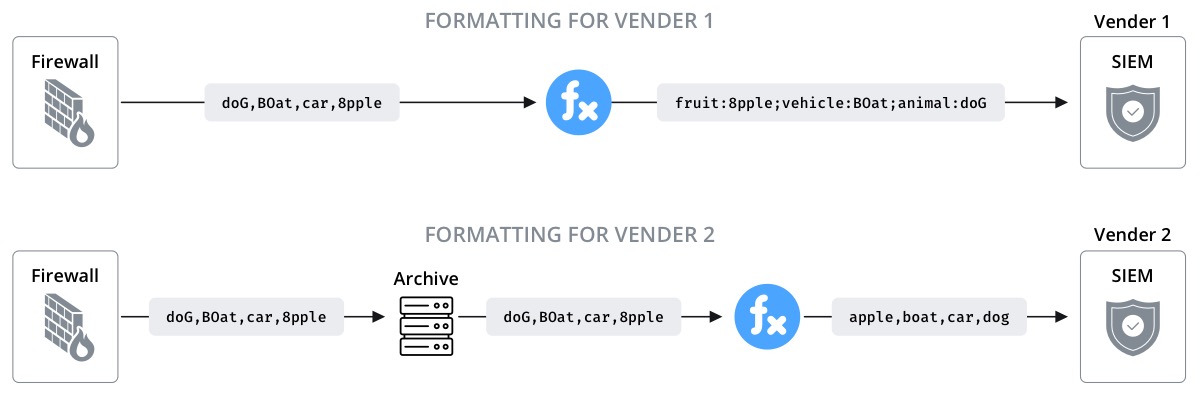
Or perhaps vendor 1 offers the best Security Information and Event Management (SIEM) tool today , but vendor 2 will do better tomorrow . How do you get all your old data into the new solution? Wouldn’t it be great if you had a complete copy of all the raw data that ever flowed through your environment?
In this course, we will learn how to configure a Pipeline to copy all raw data flowing through your environment to S3. By doing so, long-term storage will be more cost-effective. Also, we can reuse the data in new ways in the future if the need arises (hint: it will).
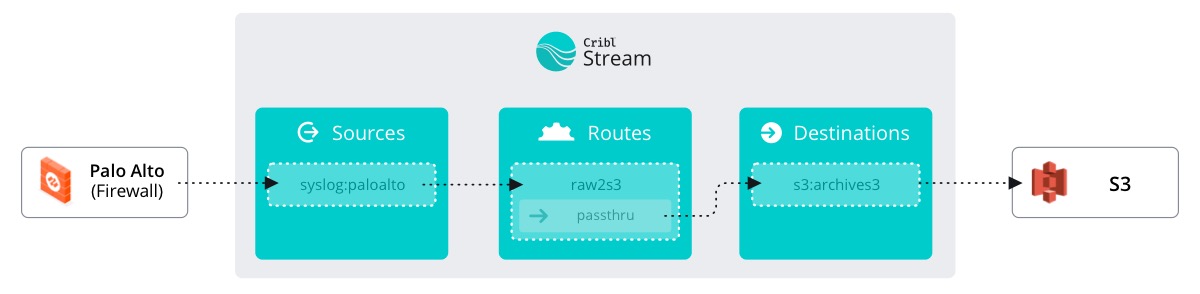
Course Map
The course map will help you to understand where you are / what you’re doing as you progress through the course. Dotted outlines indicate parts of Stream that are not yet explored. The green colored box indicates ‘You are here.’ Teal boxes indicate where you have been.